Paired TCREmp on VDJdb Full#
This notebook analyzes paired TRA/TRB embeddings from vdjdb_full.txt.gz in two modes:
Strict paired rows already containing both chains.
The same human VDJdb rows after single-chain records are repaired with missing-chain imputation.
The paired embedding is a direct concatenation of chain-specific TCREmp embeddings.
[1]:
# Configure imports, plotting, randomness, and print environment versions.
import sys
import time
import warnings
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import polars as pl
import seaborn as sns
import sklearn
import umap
from IPython.display import display
try:
import kneed
except ImportError:
kneed = None
from mir.common.parser import VDJdbFullPairedParser
from mir.common.single_cell import build_tenx_sample_from_cell_clonotypes
from mir.common.single_cell_repair import impute_missing_chains
from mir.embedding.tcremp import PairedTCREmp
from mir.utils.embedding_diagnostics import analyze_embedding_dbscan
from mir.utils.notebook_assets import ensure_airr_benchmark, find_airr_benchmark_vdjdb_full, find_repo_root
SEED = 42
np.random.seed(SEED)
# Curation note: SLLMWITQV is excluded due to technique-specific enrichment
# toward a single degenerate TCR pattern rather than broad repertoire structure.
EXCLUDED_EPITOPES = {'SLLMWITQV'}
sns.set_theme(style='whitegrid', context='talk')
plt.rcParams['figure.dpi'] = 140
plt.rcParams['savefig.dpi'] = 300
print(f'Python: {sys.version.split()[0]}')
print(f'numpy: {np.__version__}')
print(f'polars: {pl.__version__}')
print(f'pandas: {pd.__version__}')
print(f'scikit-learn: {sklearn.__version__}')
print(f'umap-learn: {umap.__version__}')
print(f'kneed: {getattr(kneed, "__version__", "not-installed")}')
print(f'Excluded epitopes in this notebook: {sorted(EXCLUDED_EPITOPES)}')
/Users/mikesh/vcs/mirpy/.venv/lib/python3.12/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Python: 3.12.12
numpy: 1.26.4
polars: 1.40.1
pandas: 3.0.3
scikit-learn: 1.8.0
umap-learn: 0.5.12
kneed: 0.8.6
Excluded epitopes in this notebook: ['SLLMWITQV']
[2]:
# Load VDJdb full rows, build strict/imputed paired datasets, and show metadata access patterns.
repo_root = find_repo_root(Path.cwd())
dataset_root = ensure_airr_benchmark(repo_root=repo_root, allow_patterns=['vdjdb/**'])
vdjdb_full = find_airr_benchmark_vdjdb_full(dataset_root)
parser = VDJdbFullPairedParser()
t0 = time.perf_counter()
strict_cell_df, strict_metadata = parser.parse_cell_clonotypes_file(
vdjdb_full,
sample_id='vdjdb_full_human_strict',
species='HomoSapiens',
include_incomplete=False,
)
strict_sample = build_tenx_sample_from_cell_clonotypes(
strict_cell_df,
sample_id='vdjdb_full_human_strict',
barcode_metadata=strict_metadata,
)
strict_runtime = time.perf_counter() - t0
t0 = time.perf_counter()
impute_input_df, impute_metadata = parser.parse_cell_clonotypes_file(
vdjdb_full,
sample_id='vdjdb_full_human_impute',
species='HomoSapiens',
include_incomplete=True,
)
imputed_cell_df = impute_missing_chains(impute_input_df)
imputed_sample = build_tenx_sample_from_cell_clonotypes(
imputed_cell_df,
sample_id='vdjdb_full_human_impute',
barcode_metadata=impute_metadata,
)
imputed_runtime = time.perf_counter() - t0
strict_pairs = strict_sample.paired_locus_repertoires['TRA_TRB'].paired_clonotypes
imputed_pairs = imputed_sample.paired_locus_repertoires['TRA_TRB'].paired_clonotypes
print(f'VDJdb full file: {vdjdb_full}')
print(f'Strict rows: {strict_cell_df.height:,} chains -> {len(strict_pairs):,} paired clonotypes ({strict_runtime:.2f}s)')
print(f'Imputed rows: {imputed_cell_df.height:,} chains -> {len(imputed_pairs):,} paired clonotypes ({imputed_runtime:.2f}s)')
print(f'Added paired clonotypes after imputation: {len(imputed_pairs) - len(strict_pairs):,}')
# Demonstration 1: direct dictionary access by VDJdb record id (synthetic barcode).
for barcode in ['993', '1007']:
meta = strict_sample.single_cell_repertoire.barcode_metadata.get(barcode, {})
print(barcode, {k: meta.get(k, '') for k in ['antigen.epitope', 'antigen.gene', 'antigen.species', 'mhc.a', 'mhc.class']})
# Demonstration 2: tabular metadata access for joins/filters.
strict_meta_df = strict_sample.single_cell_repertoire.metadata_to_polars()
print(strict_meta_df.select(['barcode', 'vdjdb_record_id', 'antigen.epitope', 'mhc.a']).head(5))
VDJdb full file: /Users/mikesh/vcs/mirpy/notebooks/assets/large/airr_benchmark/vdjdb/vdjdb-2025-12-29/vdjdb_full.txt.gz
Strict rows: 160,626 chains -> 80,313 paired clonotypes (4.95s)
Imputed rows: 252,274 chains -> 126,137 paired clonotypes (305.57s)
Added paired clonotypes after imputation: 45,824
993 {'antigen.epitope': 'HPNGYKSLSTL', 'antigen.gene': 'NS1', 'antigen.species': 'InfluenzaB', 'mhc.a': 'HLA-B*07:02', 'mhc.class': 'MHCI'}
1007 {'antigen.epitope': 'RPIIRPATL', 'antigen.gene': 'NP', 'antigen.species': 'InfluenzaB', 'mhc.a': 'HLA-B*07:02', 'mhc.class': 'MHCI'}
shape: (5, 4)
┌─────────┬─────────────────┬─────────────────┬─────────────┐
│ barcode ┆ vdjdb_record_id ┆ antigen.epitope ┆ mhc.a │
│ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ str ┆ str ┆ str │
╞═════════╪═════════════════╪═════════════════╪═════════════╡
│ 10000 ┆ 10000 ┆ GILGFVFTL ┆ HLA-A*02:01 │
│ 100000 ┆ 100000 ┆ NLVPMVATV ┆ HLA-A*02:01 │
│ 100001 ┆ 100001 ┆ NLVPMVATV ┆ HLA-A*02:01 │
│ 100002 ┆ 100002 ┆ NLVPMVATV ┆ HLA-A*02:01 │
│ 100003 ┆ 100003 ┆ NLVPMVATV ┆ HLA-A*02:01 │
└─────────┴─────────────────┴─────────────────┴─────────────┘
[3]:
# Convert paired repertoires to polars tables and build balanced strict/imputed subsets.
def paired_sample_to_table(sample):
rows = []
for pair in sample.paired_locus_repertoires['TRA_TRB'].paired_clonotypes:
chains = {pair.clonotype1.locus: pair.clonotype1, pair.clonotype2.locus: pair.clonotype2}
barcode = pair.pair_id.split('_', 1)[0]
meta = sample.single_cell_repertoire.barcode_metadata.get(barcode, {})
rows.append(
{
'pair_id': pair.pair_id,
'barcode': barcode,
'epitope': meta.get('antigen.epitope', ''),
'antigen_gene': meta.get('antigen.gene', ''),
'antigen_species': meta.get('antigen.species', ''),
'mhc_a': meta.get('mhc.a', ''),
'reference_id': meta.get('reference.id', ''),
'method_identification': meta.get('method.identification', ''),
'tra_v': chains['TRA'].v_gene,
'tra_j': chains['TRA'].j_gene,
'tra_cdr3': chains['TRA'].junction_aa,
'trb_v': chains['TRB'].v_gene,
'trb_j': chains['TRB'].j_gene,
'trb_cdr3': chains['TRB'].junction_aa,
'tra_len': len(chains['TRA'].junction_aa),
'trb_len': len(chains['TRB'].junction_aa),
'paired_cdr3_len': len(chains['TRA'].junction_aa) + len(chains['TRB'].junction_aa),
}
)
return pl.DataFrame(rows)
def add_epitope_category(df, focal_epitopes):
return df.with_columns(
pl.when(pl.col('epitope').is_in(focal_epitopes))
.then(pl.col('epitope'))
.otherwise(pl.lit('other'))
.alias('epitope_cat')
)
def seeded_sample(df, n):
if df.height <= n:
return df
return df.sample(n=n, with_replacement=False, shuffle=True, seed=SEED)
def select_balanced(df, focal_epitopes, sample_per_epitope=250, other_sample=500):
parts = []
for ep in focal_epitopes:
parts.append(seeded_sample(df.filter(pl.col('epitope_cat') == ep), sample_per_epitope))
parts.append(seeded_sample(df.filter(pl.col('epitope_cat') == 'other'), other_sample))
return pl.concat([x for x in parts if x.height > 0], how='vertical')
strict_df = paired_sample_to_table(strict_sample)
imputed_df = paired_sample_to_table(imputed_sample)
# Exclude technique-driven outlier epitopes from focal modeling diagnostics.
strict_df = strict_df.filter(~pl.col('epitope').is_in(sorted(EXCLUDED_EPITOPES)))
imputed_df = imputed_df.filter(~pl.col('epitope').is_in(sorted(EXCLUDED_EPITOPES)))
FOCAL_EPITOPES = (
strict_df.group_by('epitope')
.len()
.sort('len', descending=True)
.head(10)
.get_column('epitope')
.to_list()
)
SAMPLE_PER_EPITOPE = 250
OTHER_SAMPLE = 500
strict_df = add_epitope_category(strict_df, FOCAL_EPITOPES)
imputed_df = add_epitope_category(imputed_df, FOCAL_EPITOPES)
strict_sel = select_balanced(strict_df, FOCAL_EPITOPES, SAMPLE_PER_EPITOPE, OTHER_SAMPLE)
imputed_sel = select_balanced(imputed_df, FOCAL_EPITOPES, SAMPLE_PER_EPITOPE, OTHER_SAMPLE)
print('Focal epitopes (SLL excluded):', FOCAL_EPITOPES)
print('Strict subset size:', strict_sel.height)
print(strict_sel.group_by('epitope_cat').len().sort('len', descending=True))
print()
print('Imputed subset size:', imputed_sel.height)
print(imputed_sel.group_by('epitope_cat').len().sort('len', descending=True))
display(strict_sel.group_by('epitope_cat').len().sort('len', descending=True).to_pandas())
Focal epitopes (SLL excluded): ['KLGGALQAK', 'NLVPMVATV', 'GILGFVFTL', 'RAKFKQLL', 'AVFDRKSDAK', 'GLCTLVAML', 'IVTDFSVIK', 'FLRGRAYGL', 'LLAGIGTVPI', 'YLQPRTFLL']
Strict subset size: 3000
shape: (11, 2)
┌─────────────┬─────┐
│ epitope_cat ┆ len │
│ --- ┆ --- │
│ str ┆ u32 │
╞═════════════╪═════╡
│ other ┆ 500 │
│ NLVPMVATV ┆ 250 │
│ AVFDRKSDAK ┆ 250 │
│ GLCTLVAML ┆ 250 │
│ YLQPRTFLL ┆ 250 │
│ … ┆ … │
│ FLRGRAYGL ┆ 250 │
│ RAKFKQLL ┆ 250 │
│ IVTDFSVIK ┆ 250 │
│ LLAGIGTVPI ┆ 250 │
│ KLGGALQAK ┆ 250 │
└─────────────┴─────┘
Imputed subset size: 3000
shape: (11, 2)
┌─────────────┬─────┐
│ epitope_cat ┆ len │
│ --- ┆ --- │
│ str ┆ u32 │
╞═════════════╪═════╡
│ other ┆ 500 │
│ KLGGALQAK ┆ 250 │
│ GILGFVFTL ┆ 250 │
│ FLRGRAYGL ┆ 250 │
│ NLVPMVATV ┆ 250 │
│ … ┆ … │
│ IVTDFSVIK ┆ 250 │
│ AVFDRKSDAK ┆ 250 │
│ YLQPRTFLL ┆ 250 │
│ LLAGIGTVPI ┆ 250 │
│ GLCTLVAML ┆ 250 │
└─────────────┴─────┘
| epitope_cat | len | |
|---|---|---|
| 0 | other | 500 |
| 1 | RAKFKQLL | 250 |
| 2 | IVTDFSVIK | 250 |
| 3 | GLCTLVAML | 250 |
| 4 | KLGGALQAK | 250 |
| 5 | GILGFVFTL | 250 |
| 6 | AVFDRKSDAK | 250 |
| 7 | FLRGRAYGL | 250 |
| 8 | YLQPRTFLL | 250 |
| 9 | NLVPMVATV | 250 |
| 10 | LLAGIGTVPI | 250 |
[4]:
# Embed balanced paired subsets and report per-record throughput (paired vs single-chain sum).
strict_pair_map = {pair.pair_id: pair for pair in strict_pairs}
imputed_pair_map = {pair.pair_id: pair for pair in imputed_pairs}
strict_selected_pairs = [strict_pair_map[pair_id] for pair_id in strict_sel.get_column('pair_id').to_list()]
imputed_selected_pairs = [imputed_pair_map[pair_id] for pair_id in imputed_sel.get_column('pair_id').to_list()]
N_PROTO = 500
model = PairedTCREmp.from_defaults(species='human', locus_pair='TRA_TRB', n_prototypes=N_PROTO, junction_method='fixed_gap')
t0 = time.perf_counter()
X_strict_raw = model.embed(strict_selected_pairs)
t_strict_embed = time.perf_counter() - t0
t0 = time.perf_counter()
X_imputed_raw = model.embed(imputed_selected_pairs)
t_imputed_embed = time.perf_counter() - t0
tra_only = [pair.clonotype1 if pair.clonotype1.locus == 'TRA' else pair.clonotype2 for pair in strict_selected_pairs]
trb_only = [pair.clonotype1 if pair.clonotype1.locus == 'TRB' else pair.clonotype2 for pair in strict_selected_pairs]
t0 = time.perf_counter()
X_tra_only = model.chain1_model.embed(tra_only)
t_tra = time.perf_counter() - t0
t0 = time.perf_counter()
X_trb_only = model.chain2_model.embed(trb_only)
t_trb = time.perf_counter() - t0
print(f'Strict paired embedding: {X_strict_raw.shape} {t_strict_embed:.3f}s ({1e3 * t_strict_embed / len(strict_selected_pairs):.3f} ms/record)')
print(f'Imputed paired embedding: {X_imputed_raw.shape} {t_imputed_embed:.3f}s ({1e3 * t_imputed_embed / len(imputed_selected_pairs):.3f} ms/record)')
print(f'Strict TRA only: {t_tra:.3f}s Strict TRB only: {t_trb:.3f}s Paired/(TRA+TRB): {t_strict_embed / max(t_tra + t_trb, 1e-9):.3f}x')
Strict paired embedding: (3000, 3000) 0.094s (0.031 ms/record)
Imputed paired embedding: (3000, 3000) 0.090s (0.030 ms/record)
Strict TRA only: 0.041s Strict TRB only: 0.044s Paired/(TRA+TRB): 1.102x
[5]:
# Compute PCA variance, kneedle eps, clustering metrics, and chain-level variants.
def analyze_embedding(X_raw, labels):
analysis = analyze_embedding_dbscan(
X_raw,
labels,
seed=SEED,
pca_variance_threshold=0.90,
min_samples=3,
k_neighbors=4,
consistency_threshold=0.70,
)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
analysis['X_umap'] = umap.UMAP(
n_components=2,
n_neighbors=30,
min_dist=0.10,
metric='euclidean',
random_state=SEED,
).fit_transform(analysis['X_pca'])
return analysis
strict_labels = strict_sel.get_column('epitope_cat').to_numpy()
imputed_labels = imputed_sel.get_column('epitope_cat').to_numpy()
strict_analysis = analyze_embedding(X_strict_raw, strict_labels)
imputed_analysis = analyze_embedding(X_imputed_raw, imputed_labels)
# Chain-only analyses on strict paired records to identify which chain drives SLL behavior.
strict_tra_analysis = analyze_embedding(X_tra_only, strict_labels)
strict_trb_analysis = analyze_embedding(X_trb_only, strict_labels)
summary_df = pl.DataFrame(
[
{
'mode': 'strict-paired',
'n_pairs': len(strict_selected_pairs),
'pcs_90pct': strict_analysis['n_comp'],
'eps': strict_analysis['eps'],
'clusters': strict_analysis['n_clusters'],
'retention': strict_analysis['retention'],
'purity': strict_analysis['purity'],
'consistency_70': strict_analysis['consistency'],
'median_4nn': strict_analysis['median_4nn'],
},
{
'mode': 'imputed-paired',
'n_pairs': len(imputed_selected_pairs),
'pcs_90pct': imputed_analysis['n_comp'],
'eps': imputed_analysis['eps'],
'clusters': imputed_analysis['n_clusters'],
'retention': imputed_analysis['retention'],
'purity': imputed_analysis['purity'],
'consistency_70': imputed_analysis['consistency'],
'median_4nn': imputed_analysis['median_4nn'],
},
{
'mode': 'strict-TRA-only',
'n_pairs': len(strict_selected_pairs),
'pcs_90pct': strict_tra_analysis['n_comp'],
'eps': strict_tra_analysis['eps'],
'clusters': strict_tra_analysis['n_clusters'],
'retention': strict_tra_analysis['retention'],
'purity': strict_tra_analysis['purity'],
'consistency_70': strict_tra_analysis['consistency'],
'median_4nn': strict_tra_analysis['median_4nn'],
},
{
'mode': 'strict-TRB-only',
'n_pairs': len(strict_selected_pairs),
'pcs_90pct': strict_trb_analysis['n_comp'],
'eps': strict_trb_analysis['eps'],
'clusters': strict_trb_analysis['n_clusters'],
'retention': strict_trb_analysis['retention'],
'purity': strict_trb_analysis['purity'],
'consistency_70': strict_trb_analysis['consistency'],
'median_4nn': strict_trb_analysis['median_4nn'],
},
]
)
print(summary_df)
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
shape: (4, 9)
┌────────────┬─────────┬───────────┬──────────┬───┬───────────┬──────────┬────────────┬────────────┐
│ mode ┆ n_pairs ┆ pcs_90pct ┆ eps ┆ … ┆ retention ┆ purity ┆ consistenc ┆ median_4nn │
│ --- ┆ --- ┆ --- ┆ --- ┆ ┆ --- ┆ --- ┆ y_70 ┆ --- │
│ str ┆ i64 ┆ i64 ┆ f64 ┆ ┆ f64 ┆ f64 ┆ --- ┆ f64 │
│ ┆ ┆ ┆ ┆ ┆ ┆ ┆ f64 ┆ │
╞════════════╪═════════╪═══════════╪══════════╪═══╪═══════════╪══════════╪════════════╪════════════╡
│ strict-pai ┆ 3000 ┆ 62 ┆ 0.717217 ┆ … ┆ 0.678333 ┆ 0.564754 ┆ 0.259615 ┆ 0.733947 │
│ red ┆ ┆ ┆ ┆ ┆ ┆ ┆ ┆ │
│ imputed-pa ┆ 3000 ┆ 62 ┆ 0.738993 ┆ … ┆ 0.745333 ┆ 0.508441 ┆ 0.202703 ┆ 0.751182 │
│ ired ┆ ┆ ┆ ┆ ┆ ┆ ┆ ┆ │
│ strict-TRA ┆ 3000 ┆ 40 ┆ 0.318535 ┆ … ┆ 0.597 ┆ 0.540373 ┆ 0.246512 ┆ 0.364602 │
│ -only ┆ ┆ ┆ ┆ ┆ ┆ ┆ ┆ │
│ strict-TRB ┆ 3000 ┆ 25 ┆ 0.28915 ┆ … ┆ 0.635667 ┆ 0.534971 ┆ 0.221053 ┆ 0.299993 │
│ -only ┆ ┆ ┆ ┆ ┆ ┆ ┆ ┆ │
└────────────┴─────────┴───────────┴──────────┴───┴───────────┴──────────┴────────────┴────────────┘
[6]:
# Show styled summary table for readability.
display(
summary_df.to_pandas().style
.background_gradient(subset=['purity', 'consistency_70', 'retention'], cmap='YlGnBu')
.format(precision=3)
)
| mode | n_pairs | pcs_90pct | eps | clusters | retention | purity | consistency_70 | median_4nn | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | strict-paired | 3000 | 62 | 0.717 | 104 | 0.678 | 0.565 | 0.260 | 0.734 |
| 1 | imputed-paired | 3000 | 62 | 0.739 | 74 | 0.745 | 0.508 | 0.203 | 0.751 |
| 2 | strict-TRA-only | 3000 | 40 | 0.319 | 215 | 0.597 | 0.540 | 0.247 | 0.365 |
| 3 | strict-TRB-only | 3000 | 25 | 0.289 | 190 | 0.636 | 0.535 | 0.221 | 0.300 |
[7]:
# Plot PCA variance explained and kneedle curves for strict vs imputed paired embeddings.
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
for ax, analysis, title, color in [
(axes[0, 0], strict_analysis, 'Strict paired', '#1f77b4'),
(axes[0, 1], imputed_analysis, 'Imputed paired', '#d62728'),
]:
max_show = min(200, len(analysis['cum']))
ax.plot(np.arange(1, max_show + 1), analysis['cum'][:max_show] * 100, color=color, lw=1.8)
ax.axhline(90, color='black', ls='--', lw=1.0)
ax.axvline(analysis['n_comp'], color='black', ls=':', lw=1.0)
ax.set_title(f'{title} PCA cumulative variance')
ax.set_xlabel('PC index')
ax.set_ylabel('Cumulative variance (%)')
ax.set_ylim(0, 101)
for ax, analysis, title, color in [
(axes[1, 0], strict_analysis, 'Strict paired', '#1f77b4'),
(axes[1, 1], imputed_analysis, 'Imputed paired', '#d62728'),
]:
ax.plot(analysis['kth'], color=color, lw=1.4)
if analysis['knee_idx'] is not None:
ax.axvline(analysis['knee_idx'], color='black', ls='--', lw=1.0)
ax.axhline(analysis['eps'], color='black', ls=':', lw=1.0)
ax.set_title(f'{title} kneedle (4-NN)')
ax.set_xlabel('Sorted point index')
ax.set_ylabel('4-NN distance')
plt.tight_layout()
plt.show()
print('Strict paired: eps={:.4f}, PCs@90%={}, clusters={}, retention={:.3f}, purity={:.3f}, consistency={:.3f}'.format(
strict_analysis['eps'], strict_analysis['n_comp'], strict_analysis['n_clusters'], strict_analysis['retention'], strict_analysis['purity'], strict_analysis['consistency']
))
print('Imputed paired: eps={:.4f}, PCs@90%={}, clusters={}, retention={:.3f}, purity={:.3f}, consistency={:.3f}'.format(
imputed_analysis['eps'], imputed_analysis['n_comp'], imputed_analysis['n_clusters'], imputed_analysis['retention'], imputed_analysis['purity'], imputed_analysis['consistency']
))
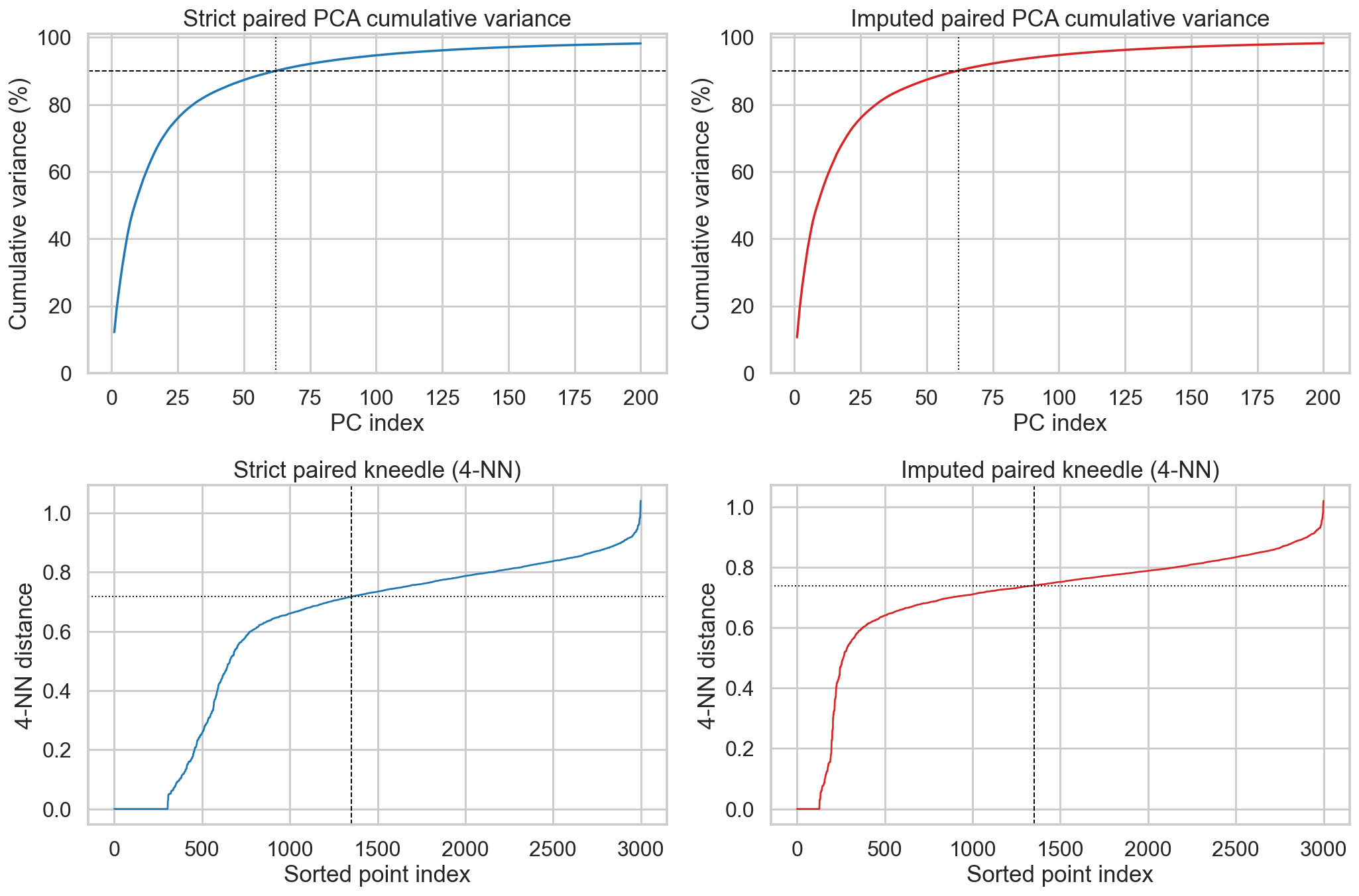
Strict paired: eps=0.7172, PCs@90%=62, clusters=104, retention=0.678, purity=0.565, consistency=0.260
Imputed paired: eps=0.7390, PCs@90%=62, clusters=74, retention=0.745, purity=0.508, consistency=0.203
[8]:
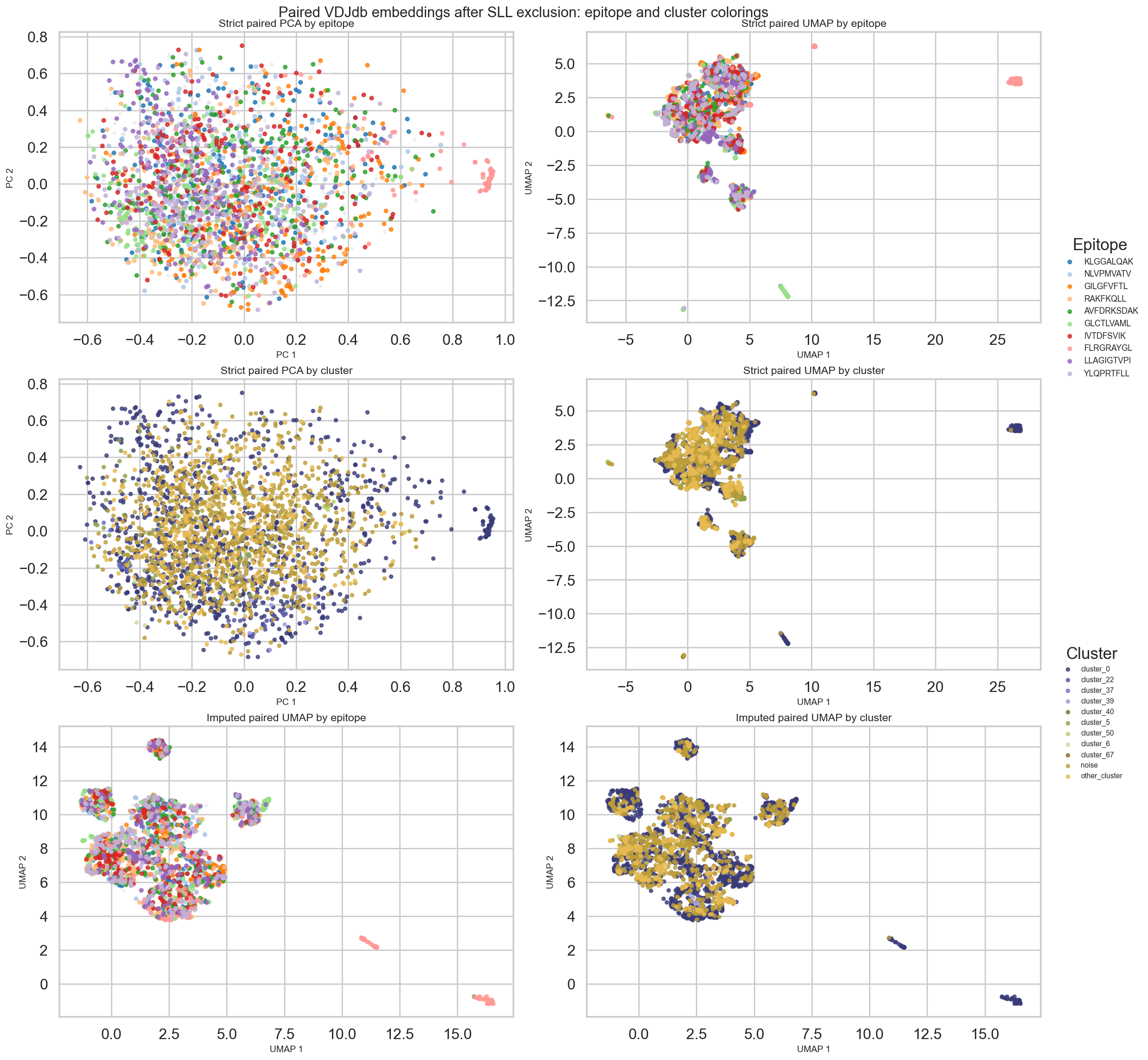
# Visualize paired embeddings by epitope, by cluster, and by chain-level features.
palette_keys = FOCAL_EPITOPES + ['other']
palette_values = sns.color_palette('tab20', n_colors=len(FOCAL_EPITOPES)) + [(0.80, 0.80, 0.80)]
PALETTE = dict(zip(palette_keys, palette_values))
def scatter_epitopes(ax, coords, labels, title, xlabel, ylabel):
labels = np.asarray(labels)
mask_other = labels == 'other'
ax.scatter(coords[mask_other, 0], coords[mask_other, 1], s=9, alpha=0.20, color=PALETTE['other'], rasterized=True)
for epitope in FOCAL_EPITOPES:
mask = labels == epitope
if mask.sum() == 0:
continue
ax.scatter(coords[mask, 0], coords[mask, 1], s=14, alpha=0.78, color=PALETTE[epitope], rasterized=True, label=epitope)
ax.set_title(title, fontsize=12)
ax.set_xlabel(xlabel, fontsize=10)
ax.set_ylabel(ylabel, fontsize=10)
def scatter_clusters(ax, coords, clusters, title, xlabel, ylabel):
cluster_labels = np.array([f'cluster_{c}' if c != -1 else 'noise' for c in clusters])
uniq, counts = np.unique(cluster_labels, return_counts=True)
order = np.argsort(-counts)
top = set(uniq[order[:10]])
cluster_disp = np.array([cl if cl in top or cl == 'noise' else 'other_cluster' for cl in cluster_labels])
palette = sns.color_palette('tab20b', n_colors=len(np.unique(cluster_disp)))
for i, cl in enumerate(np.unique(cluster_disp)):
mask = cluster_disp == cl
ax.scatter(coords[mask, 0], coords[mask, 1], s=12, alpha=0.75, color=palette[i], rasterized=True, label=cl)
ax.set_title(title, fontsize=12)
ax.set_xlabel(xlabel, fontsize=10)
ax.set_ylabel(ylabel, fontsize=10)
fig, axes = plt.subplots(3, 2, figsize=(16, 16), constrained_layout=True)
scatter_epitopes(axes[0, 0], strict_analysis['X_pca'][:, :2], strict_labels, 'Strict paired PCA by epitope', 'PC 1', 'PC 2')
scatter_epitopes(axes[0, 1], strict_analysis['X_umap'], strict_labels, 'Strict paired UMAP by epitope', 'UMAP 1', 'UMAP 2')
scatter_clusters(axes[1, 0], strict_analysis['X_pca'][:, :2], strict_analysis['clusters'], 'Strict paired PCA by cluster', 'PC 1', 'PC 2')
scatter_clusters(axes[1, 1], strict_analysis['X_umap'], strict_analysis['clusters'], 'Strict paired UMAP by cluster', 'UMAP 1', 'UMAP 2')
scatter_epitopes(axes[2, 0], imputed_analysis['X_umap'], imputed_labels, 'Imputed paired UMAP by epitope', 'UMAP 1', 'UMAP 2')
scatter_clusters(axes[2, 1], imputed_analysis['X_umap'], imputed_analysis['clusters'], 'Imputed paired UMAP by cluster', 'UMAP 1', 'UMAP 2')
for r in range(3):
for c in range(2):
if axes[r, c].legend_ is not None:
axes[r, c].legend_.remove()
handles_e, labels_e = axes[0, 1].get_legend_handles_labels()
handles_c, labels_c = axes[1, 1].get_legend_handles_labels()
fig.legend(handles_e, labels_e, loc='center left', bbox_to_anchor=(1.01, 0.72), frameon=False, title='Epitope', fontsize=9)
fig.legend(handles_c, labels_c, loc='center left', bbox_to_anchor=(1.01, 0.33), frameon=False, title='Cluster', fontsize=8)
fig.suptitle('Paired VDJdb embeddings after SLL exclusion: epitope and cluster colorings', fontsize=16, y=1.01)
plt.show()
def top_categories(values, top_n=8):
uniq, counts = np.unique(values, return_counts=True)
order = np.argsort(-counts)
top = set(uniq[order[:top_n]])
return np.array([v if v in top else 'other' for v in values])
strict_tra_v = top_categories(strict_sel.get_column('tra_v').to_numpy())
strict_trb_v = top_categories(strict_sel.get_column('trb_v').to_numpy())
strict_tra_j = top_categories(strict_sel.get_column('tra_j').to_numpy())
strict_trb_j = top_categories(strict_sel.get_column('trb_j').to_numpy())
strict_tra_len = strict_sel.get_column('tra_len').to_numpy()
strict_trb_len = strict_sel.get_column('trb_len').to_numpy()
fig, axes = plt.subplots(2, 3, figsize=(18, 11), constrained_layout=True)
for ax, values, title in [
(axes[0, 0], strict_tra_v, 'Strict paired PCA color: TRA V'),
(axes[0, 1], strict_tra_j, 'Strict paired PCA color: TRA J'),
(axes[0, 2], strict_tra_len, 'Strict paired PCA color: TRA CDR3 length'),
(axes[1, 0], strict_trb_v, 'Strict paired PCA color: TRB V'),
(axes[1, 1], strict_trb_j, 'Strict paired PCA color: TRB J'),
(axes[1, 2], strict_trb_len, 'Strict paired PCA color: TRB CDR3 length'),
]:
if values.dtype.kind in {'U', 'O'}:
cats = np.unique(values)
cmap = sns.color_palette('tab10', n_colors=len(cats))
for c_idx, cat in enumerate(cats):
mask = values == cat
ax.scatter(strict_analysis['X_pca'][mask, 0], strict_analysis['X_pca'][mask, 1], s=10, alpha=0.68, color=cmap[c_idx], rasterized=True, label=cat if c_idx < 8 else None)
else:
sc = ax.scatter(strict_analysis['X_pca'][:, 0], strict_analysis['X_pca'][:, 1], c=values, cmap='viridis', s=10, alpha=0.68, rasterized=True)
plt.colorbar(sc, ax=ax, fraction=0.046, pad=0.04)
ax.set_title(title, fontsize=11)
ax.set_xlabel('PC 1', fontsize=10)
ax.set_ylabel('PC 2', fontsize=10)
plt.show()
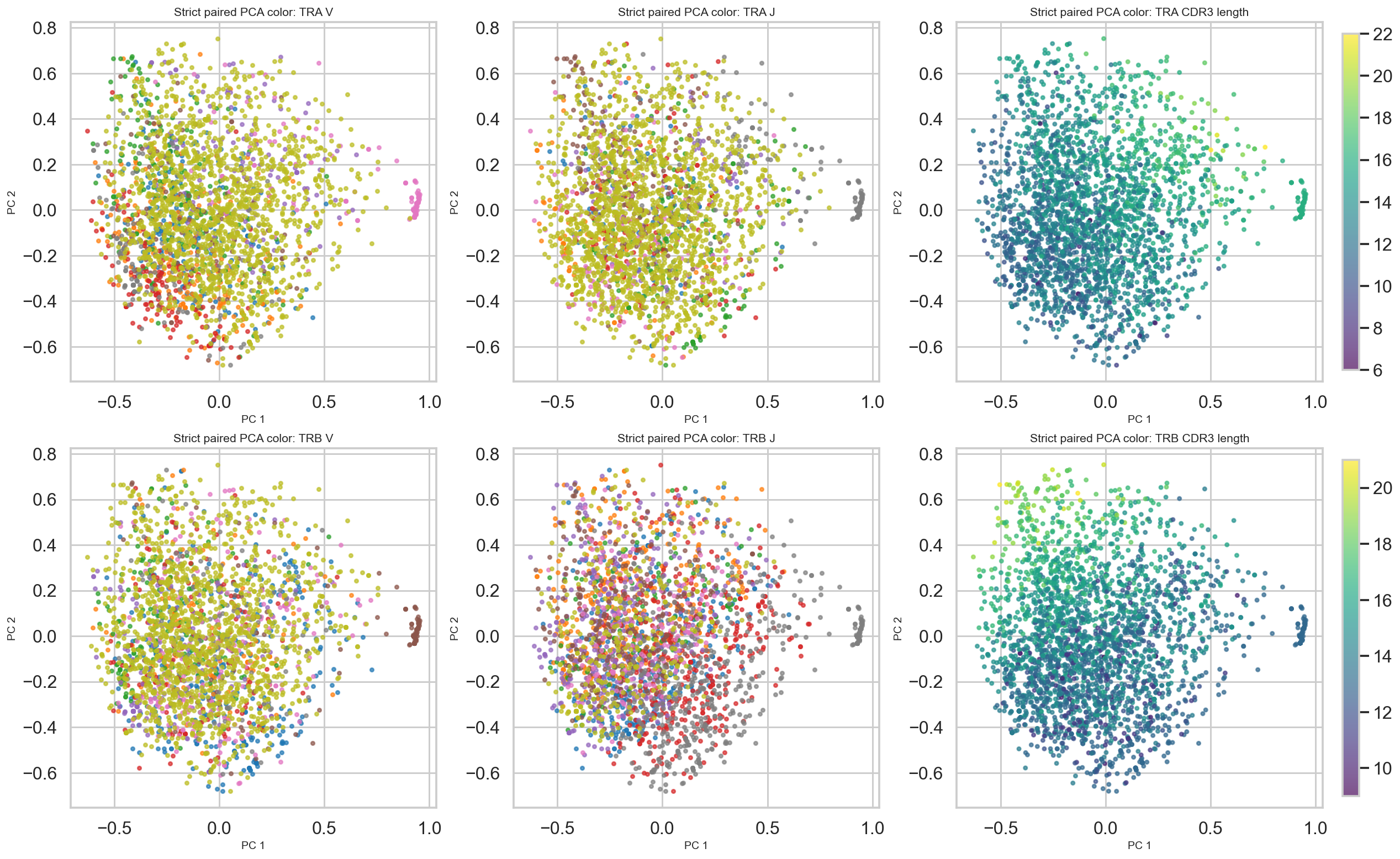
[9]:
# Diagnose outliers after explicit SLL exclusion and report FLR enrichment.
TARGET_EPITOPE = 'FLRGRAYGL'
PHAGE_REFERENCE = 'PMID:40498839'
def epitope_distance_profile(coords, labels):
global_centroid = coords.mean(axis=0)
rows = []
for ep in np.unique(labels):
mask = labels == ep
ep_coords = coords[mask]
ep_centroid = ep_coords.mean(axis=0)
intra = np.linalg.norm(ep_coords - ep_centroid, axis=1)
inter = np.linalg.norm(ep_coords - global_centroid, axis=1)
rows.append(
{
'epitope': ep,
'n': int(mask.sum()),
'mean_intra_dist': float(intra.mean()),
'mean_global_dist': float(inter.mean()),
}
)
return pl.DataFrame(rows).sort('mean_global_dist', descending=True)
def is_phage_display_expr() -> pl.Expr:
method = pl.col('method_identification').fill_null('').str.to_lowercase()
ref = pl.col('reference_id').fill_null('')
return method.str.contains('phage') | (ref == PHAGE_REFERENCE)
def enriched_vj(table, target_epitope, chain='tra', top_n=8):
v_col = f'{chain}_v'
j_col = f'{chain}_j'
target = table.filter(pl.col('epitope') == target_epitope)
background = table.filter(pl.col('epitope') != target_epitope)
if target.height == 0 or background.height == 0:
return pl.DataFrame({'v': [], 'j': [], 'target_n': [], 'target_frac': [], 'background_frac': [], 'log2_enrichment': []})
target_counts = target.group_by([v_col, j_col]).len().rename({'len': 'target_n'})
background_counts = background.group_by([v_col, j_col]).len().rename({'len': 'background_n'})
target_total = float(target.height)
background_total = float(background.height)
return (
target_counts.join(background_counts, on=[v_col, j_col], how='left')
.with_columns(
pl.col('background_n').fill_null(0),
(pl.col('target_n') / target_total).alias('target_frac'),
(pl.col('background_n') / background_total).alias('background_frac'),
)
.with_columns(
((pl.col('target_frac') + 1e-6) / (pl.col('background_frac') + 1e-6)).log(base=2).alias('log2_enrichment')
)
.sort(['log2_enrichment', 'target_n'], descending=[True, True])
.head(top_n)
.rename({v_col: 'v', j_col: 'j'})
.select(['v', 'j', 'target_n', 'target_frac', 'background_frac', 'log2_enrichment'])
)
strict_profile_paired = epitope_distance_profile(strict_analysis['X_pca'], strict_labels)
strict_profile_tra = epitope_distance_profile(strict_tra_analysis['X_pca'], strict_labels)
strict_profile_trb = epitope_distance_profile(strict_trb_analysis['X_pca'], strict_labels)
print('Outlier ranking in strict paired PCA (higher mean_global_dist = more outlying):')
print(strict_profile_paired.head(8))
print('\nOutlier ranking in strict TRA-only PCA:')
print(strict_profile_tra.head(8))
print('\nOutlier ranking in strict TRB-only PCA:')
print(strict_profile_trb.head(8))
flr_rank_paired = strict_profile_paired.with_row_index().filter(pl.col('epitope') == TARGET_EPITOPE)[0, 'index'] + 1
flr_rank_tra = strict_profile_tra.with_row_index().filter(pl.col('epitope') == TARGET_EPITOPE)[0, 'index'] + 1
flr_rank_trb = strict_profile_trb.with_row_index().filter(pl.col('epitope') == TARGET_EPITOPE)[0, 'index'] + 1
print(f"\nFLR outlier rank: paired={flr_rank_paired}, TRA-only={flr_rank_tra}, TRB-only={flr_rank_trb}")
print('\nTop enriched TRA V/J for FLRGRAYGL:')
print(enriched_vj(strict_df, 'FLRGRAYGL', chain='tra', top_n=8))
print('\nTop enriched TRB V/J for FLRGRAYGL:')
print(enriched_vj(strict_df, 'FLRGRAYGL', chain='trb', top_n=8))
Outlier ranking in strict paired PCA (higher mean_global_dist = more outlying):
shape: (8, 4)
┌────────────┬─────┬─────────────────┬──────────────────┐
│ epitope ┆ n ┆ mean_intra_dist ┆ mean_global_dist │
│ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ i64 ┆ f64 ┆ f64 │
╞════════════╪═════╪═════════════════╪══════════════════╡
│ IVTDFSVIK ┆ 250 ┆ 0.982779 ┆ 1.000975 │
│ AVFDRKSDAK ┆ 250 ┆ 0.993868 ┆ 1.000735 │
│ other ┆ 500 ┆ 0.993849 ┆ 1.000527 │
│ NLVPMVATV ┆ 250 ┆ 0.993313 ┆ 1.000456 │
│ KLGGALQAK ┆ 250 ┆ 0.993967 ┆ 1.000437 │
│ LLAGIGTVPI ┆ 250 ┆ 0.92092 ┆ 1.000204 │
│ GLCTLVAML ┆ 250 ┆ 0.941127 ┆ 0.999622 │
│ FLRGRAYGL ┆ 250 ┆ 0.341326 ┆ 0.998977 │
└────────────┴─────┴─────────────────┴──────────────────┘
Outlier ranking in strict TRA-only PCA:
shape: (8, 4)
┌────────────┬─────┬─────────────────┬──────────────────┐
│ epitope ┆ n ┆ mean_intra_dist ┆ mean_global_dist │
│ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ i64 ┆ f64 ┆ f64 │
╞════════════╪═════╪═════════════════╪══════════════════╡
│ FLRGRAYGL ┆ 250 ┆ 0.34302 ┆ 1.019087 │
│ GILGFVFTL ┆ 250 ┆ 0.937323 ┆ 1.003035 │
│ AVFDRKSDAK ┆ 250 ┆ 0.990336 ┆ 1.00013 │
│ IVTDFSVIK ┆ 250 ┆ 0.976467 ┆ 0.999805 │
│ NLVPMVATV ┆ 250 ┆ 0.990112 ┆ 0.999394 │
│ other ┆ 500 ┆ 0.9935 ┆ 0.999081 │
│ KLGGALQAK ┆ 250 ┆ 0.99339 ┆ 0.999041 │
│ RAKFKQLL ┆ 250 ┆ 0.944118 ┆ 0.997669 │
└────────────┴─────┴─────────────────┴──────────────────┘
Outlier ranking in strict TRB-only PCA:
shape: (8, 4)
┌────────────┬─────┬─────────────────┬──────────────────┐
│ epitope ┆ n ┆ mean_intra_dist ┆ mean_global_dist │
│ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ i64 ┆ f64 ┆ f64 │
╞════════════╪═════╪═════════════════╪══════════════════╡
│ LLAGIGTVPI ┆ 250 ┆ 0.98697 ┆ 1.007295 │
│ GLCTLVAML ┆ 250 ┆ 0.941345 ┆ 1.005727 │
│ IVTDFSVIK ┆ 250 ┆ 0.984157 ┆ 1.003129 │
│ other ┆ 500 ┆ 0.994459 ┆ 1.00295 │
│ KLGGALQAK ┆ 250 ┆ 0.994151 ┆ 1.002048 │
│ AVFDRKSDAK ┆ 250 ┆ 0.997422 ┆ 1.00191 │
│ NLVPMVATV ┆ 250 ┆ 0.996075 ┆ 1.001338 │
│ YLQPRTFLL ┆ 250 ┆ 0.955683 ┆ 0.997374 │
└────────────┴─────┴─────────────────┴──────────────────┘
FLR outlier rank: paired=8, TRA-only=1, TRB-only=11
Top enriched TRA V/J for FLRGRAYGL:
shape: (8, 6)
┌─────────────┬───────────┬──────────┬─────────────┬─────────────────┬─────────────────┐
│ v ┆ j ┆ target_n ┆ target_frac ┆ background_frac ┆ log2_enrichment │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ str ┆ u32 ┆ f64 ┆ f64 ┆ f64 │
╞═════════════╪═══════════╪══════════╪═════════════╪═════════════════╪═════════════════╡
│ TRAV26-2*01 ┆ TRAJ52*01 ┆ 456 ┆ 0.820144 ┆ 0.001399 ┆ 9.194143 │
│ TRAV4*01 ┆ TRAJ52*01 ┆ 3 ┆ 0.005396 ┆ 0.00006 ┆ 6.467971 │
│ TRAV3*01 ┆ TRAJ30*01 ┆ 28 ┆ 0.05036 ┆ 0.000939 ┆ 5.742825 │
│ TRAV30*01 ┆ TRAJ29*01 ┆ 4 ┆ 0.007194 ┆ 0.00016 ┆ 5.482771 │
│ TRAV2*01 ┆ TRAJ13*01 ┆ 4 ┆ 0.007194 ┆ 0.0002 ┆ 5.162637 │
│ TRAV26-1*01 ┆ TRAJ44*01 ┆ 1 ┆ 0.001799 ┆ 0.00008 ┆ 4.474434 │
│ TRAV22*01 ┆ TRAJ13*01 ┆ 1 ┆ 0.001799 ┆ 0.00012 ┆ 3.895424 │
│ TRAV12-2*01 ┆ TRAJ27*01 ┆ 6 ┆ 0.010791 ┆ 0.000879 ┆ 3.61559 │
└─────────────┴───────────┴──────────┴─────────────┴─────────────────┴─────────────────┘
Top enriched TRB V/J for FLRGRAYGL:
shape: (8, 6)
┌────────────┬────────────┬──────────┬─────────────┬─────────────────┬─────────────────┐
│ v ┆ j ┆ target_n ┆ target_frac ┆ background_frac ┆ log2_enrichment │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ str ┆ u32 ┆ f64 ┆ f64 ┆ f64 │
╞════════════╪════════════╪══════════╪═════════════╪═════════════════╪═════════════════╡
│ TRBV6S3*01 ┆ TRBJ2-1*01 ┆ 5 ┆ 0.008993 ┆ null ┆ null │
│ TRBV7-8*01 ┆ TRBJ2-7*01 ┆ 451 ┆ 0.811151 ┆ 0.002978 ┆ 8.088897 │
│ TRBV6-2*01 ┆ TRBJ2-4*01 ┆ 1 ┆ 0.001799 ┆ 0.00002 ┆ 6.421936 │
│ TRBV6-4*01 ┆ TRBJ1-6*01 ┆ 5 ┆ 0.008993 ┆ 0.00022 ┆ 5.347675 │
│ TRBV7-6*01 ┆ TRBJ2-1*01 ┆ 28 ┆ 0.05036 ┆ 0.002459 ┆ 4.355847 │
│ TRBV7-6*01 ┆ TRBJ2-7*01 ┆ 10 ┆ 0.017986 ┆ 0.002099 ┆ 3.09864 │
│ TRBV6-1*01 ┆ TRBJ1-4*01 ┆ 2 ┆ 0.003597 ┆ 0.00068 ┆ 2.402382 │
│ TRBV2*01 ┆ TRBJ1-2*01 ┆ 6 ┆ 0.010791 ┆ 0.002299 ┆ 2.230543 │
└────────────┴────────────┴──────────┴─────────────┴─────────────────┴─────────────────┘
[10]:
# Print compact exclusion and FLR summary for downstream reporting.
vdjdb_all = pl.read_csv(vdjdb_full, separator='\t', null_values=['', 'NA'], ignore_errors=True)
sll_all = vdjdb_all.filter(pl.col('antigen.epitope') == 'SLLMWITQV')
phage_all_n = sll_all.filter(
pl.col('method.identification').cast(pl.Utf8).fill_null('').str.to_lowercase().str.contains('phage')
| (pl.col('reference.id').cast(pl.Utf8).fill_null('') == PHAGE_REFERENCE)
).height
print({'sll_total_vdjdb_all': sll_all.height, 'sll_phage_vdjdb_all': phage_all_n})
print('SLLMWITQV kept in strict_df after exclusion:', strict_df.filter(pl.col('epitope') == 'SLLMWITQV').height)
flr_tra_top3 = enriched_vj(strict_df, 'FLRGRAYGL', chain='tra', top_n=3)
flr_trb_top3 = enriched_vj(strict_df, 'FLRGRAYGL', chain='trb', top_n=3)
print('Top FLR TRA V/J:\n', flr_tra_top3)
print('Top FLR TRB V/J:\n', flr_trb_top3)
display(flr_tra_top3.to_pandas().style.background_gradient(subset=['log2_enrichment'], cmap='YlGnBu').format(precision=3))
display(flr_trb_top3.to_pandas().style.background_gradient(subset=['log2_enrichment'], cmap='YlGnBu').format(precision=3))
{'sll_total_vdjdb_all': 29727, 'sll_phage_vdjdb_all': 29715}
SLLMWITQV kept in strict_df after exclusion: 0
Top FLR TRA V/J:
shape: (3, 6)
┌─────────────┬───────────┬──────────┬─────────────┬─────────────────┬─────────────────┐
│ v ┆ j ┆ target_n ┆ target_frac ┆ background_frac ┆ log2_enrichment │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ str ┆ u32 ┆ f64 ┆ f64 ┆ f64 │
╞═════════════╪═══════════╪══════════╪═════════════╪═════════════════╪═════════════════╡
│ TRAV26-2*01 ┆ TRAJ52*01 ┆ 456 ┆ 0.820144 ┆ 0.001399 ┆ 9.194143 │
│ TRAV4*01 ┆ TRAJ52*01 ┆ 3 ┆ 0.005396 ┆ 0.00006 ┆ 6.467971 │
│ TRAV3*01 ┆ TRAJ30*01 ┆ 28 ┆ 0.05036 ┆ 0.000939 ┆ 5.742825 │
└─────────────┴───────────┴──────────┴─────────────┴─────────────────┴─────────────────┘
Top FLR TRB V/J:
shape: (3, 6)
┌────────────┬────────────┬──────────┬─────────────┬─────────────────┬─────────────────┐
│ v ┆ j ┆ target_n ┆ target_frac ┆ background_frac ┆ log2_enrichment │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ str ┆ u32 ┆ f64 ┆ f64 ┆ f64 │
╞════════════╪════════════╪══════════╪═════════════╪═════════════════╪═════════════════╡
│ TRBV6S3*01 ┆ TRBJ2-1*01 ┆ 5 ┆ 0.008993 ┆ null ┆ null │
│ TRBV7-8*01 ┆ TRBJ2-7*01 ┆ 451 ┆ 0.811151 ┆ 0.002978 ┆ 8.088897 │
│ TRBV6-2*01 ┆ TRBJ2-4*01 ┆ 1 ┆ 0.001799 ┆ 0.00002 ┆ 6.421936 │
└────────────┴────────────┴──────────┴─────────────┴─────────────────┴─────────────────┘
| v | j | target_n | target_frac | background_frac | log2_enrichment | |
|---|---|---|---|---|---|---|
| 0 | TRAV26-2*01 | TRAJ52*01 | 456 | 0.820 | 0.001 | 9.194 |
| 1 | TRAV4*01 | TRAJ52*01 | 3 | 0.005 | 0.000 | 6.468 |
| 2 | TRAV3*01 | TRAJ30*01 | 28 | 0.050 | 0.001 | 5.743 |
| v | j | target_n | target_frac | background_frac | log2_enrichment | |
|---|---|---|---|---|---|---|
| 0 | TRBV6S3*01 | TRBJ2-1*01 | 5 | 0.009 | nan | nan |
| 1 | TRBV7-8*01 | TRBJ2-7*01 | 451 | 0.811 | 0.003 | 8.089 |
| 2 | TRBV6-2*01 | TRBJ2-4*01 | 1 | 0.002 | 0.000 | 6.422 |
Final notes#
The paired VDJdb analysis excludes
SLLMWITQVfrom focal embedding diagnostics.Rationale: this epitope is driven by technique-specific enrichment around a single degenerate TCR pattern, which can distort broader repertoire geometry.
Provenance counts are still reported for transparency, while interpretation centers on non-excluded epitopes.
[11]:
# Emit concise text summary for manuscript-style reporting.
print('Summary')
print('-------')
print(f"Strict paired embedding retention: {strict_analysis['retention']:.3f}")
print(f"Imputed paired embedding retention: {imputed_analysis['retention']:.3f}")
for row in summary_df.sort('purity', descending=True).iter_rows(named=True):
print(
f"{row['mode']}: eps={row['eps']:.3f}, clusters={int(row['clusters'])}, "
f"purity={row['purity']:.3f}, consistency@0.70={row['consistency_70']:.3f}, "
f"retention={row['retention']:.3f}, median_4nn={row['median_4nn']:.3f}"
)
print('\nExclusion policy: SLLMWITQV was excluded from focal diagnostics due to technique-specific degenerate-pattern enrichment.')
print('Key finding: FLRGRAYGL shows strong TRA-driven enrichment with distinctive V/J pairing signatures and remains separable in paired UMAP space.')
Summary
-------
Strict paired embedding retention: 0.678
Imputed paired embedding retention: 0.745
strict-paired: eps=0.717, clusters=104, purity=0.565, consistency@0.70=0.260, retention=0.678, median_4nn=0.734
strict-TRA-only: eps=0.319, clusters=215, purity=0.540, consistency@0.70=0.247, retention=0.597, median_4nn=0.365
strict-TRB-only: eps=0.289, clusters=190, purity=0.535, consistency@0.70=0.221, retention=0.636, median_4nn=0.300
imputed-paired: eps=0.739, clusters=74, purity=0.508, consistency@0.70=0.203, retention=0.745, median_4nn=0.751
Exclusion policy: SLLMWITQV was excluded from focal diagnostics due to technique-specific degenerate-pattern enrichment.
Key finding: FLRGRAYGL shows strong TRA-driven enrichment with distinctive V/J pairing signatures and remains separable in paired UMAP space.